William Of Ockham is one of the few medieval theologian/philosophers whose name survives today, thanks to his formulation of the principle known as Occam’s Razor. In the original latin, if you want to show off, it runs Non sunt multiplicanda entia sine necessitate, or Entities are not to be multiplied without necessity, which can be loosely paraphrased as The simplest explanation is the best one, an idea that is as attractive to a 21st century audience as it was back in the 14th.

Now fast forward a few centuries and let’s try and apply this to the neutrino. People talk about the “Dirac Neutrino” but that’s a bit off-target. Paul Dirac produced the definitive description not of the neutrino but of the electron. The Dirac Equation shows – as explained in countless graduate physics courses – that there have to be 2×2=4 types of electron: there are the usual negatively charged ones and the rarer positively charged ones (usually known as positrons), and for each of these the intrinsic spin can point along the direction of motion (‘right handed’) or against it (‘left handed’). The charge is a basic property that can’t change, but handedness depends on the observer (if you and I observe and discuss electrons while the two of us are moving, we will agree about their directions of spin but not about their directions of motion.)

Dirac worked all this out to describe how the electron experienced the electromagnetic force. But it turned out to be the key to describing its behaviour in the beta-decay weak force as well. But with a twist. Only the left handed electron and the right handed positron ‘feel’ the weak force. If you show a right handed electron or a left handed positron to the W particle that’s responsible for the weak force then it’s just not interested. This seems weird but has been very firmly established by decades of precision experiments.
(If you’re worried that this preference appears to contradict the statement earlier that handedness is observer-dependent then well done! Let’s just say I’ve oversimplified a bit, and the mathematics really does take care of it properly. Give yourself a gold star, and check out the difference between ‘helicity’ and ‘chiralilty’ sometime.)
Right, that’s enough about electrons, let’s move on to neutrinos. They also interact weakly, very similarly to the electron: only the left-handed neutrino and the right-handed antineutrino are involved, and the right-handed neutrino and left-handed antineutrino don’t.
But it’s worse than that. The left handed neutrino and right handed antineutrino don’t interact weakly: they also don’t interact electromagnetically because the neutrino, unlike the electron, is neutral. And they don’t interact strongly either. In fact they don’t interact full stop.
And this is where William comes in wielding his razor. Our list of fundamental particles includes this absolutely pointless pair that don’t participate at all. What’s the point of them? Can’t we rewrite our description in a way that leaves them out?
And it turns out that we can.

Ettore Majorana, very soon after Dirac published his equation for the electron, pointed out that for neutral particles a simpler outcome was possible. In his system the ‘antiparticle’ of the left-handed neutrino is the right-handed neutrino. The neutrino, like the photon, is self-conjugate. The experiments that showed that neutrinos and antineutrinos were distinct (neutrinos produce electrons in targets: antineutrinos produce positrons) in fact showed the difference between left-handed and right-handed neutrinos. There are only 2 neutrinos and they both interact, not 2×2 where two of the foursome just play gooseberry.
So hooray for simplicity. But is it?
The electron (and its heavier counterparts, the mu and the tau) is certainly a Dirac particle. So are the quarks, both the 2/3 and the -1/3 varieties. If all the other fundamental fermions are Dirac particles, isn’t it simpler that the neutrino is cut to the same pattern, rather than having its own special prescription? If we understand electrons – which it is fair to say that we do – isn’t it simpler that the neutrino be just a neutral version of the electron, rather than some new entity introduced specially for the purpose?
And that’s where we are. It’s all very well advocating “the simple solution” but how can you tell what’s simple? The jury is still out. Hopefully a future set of experiments (on neutrinoless double beta decay) will give an answer on whether a neutrino can be its own antiparticle, though these are very tough and will take several years. After which we will doubtless see with hindsight the simplicity of the answer, whichever it is, and tell each other that it should have been obvious thanks to William. But at the moment he’s not really much help.






 So going back to the experiment, the probability that random background would give a signal like this may be 1 in 20,000 but that’s not the probability that this signal was produced by random background: that also depends on the probabilities we assign to the mundane random background or the exotic axion. Despite this 1 in 20,000 figure I very much doubt that you’d find a particle physicist outside the Xenon1T collaboration who’d give you as much as even odds on the axion theory turning out to be the right one. (Possibly also inside the collaboration, but it’s not polite to ask.)
So going back to the experiment, the probability that random background would give a signal like this may be 1 in 20,000 but that’s not the probability that this signal was produced by random background: that also depends on the probabilities we assign to the mundane random background or the exotic axion. Despite this 1 in 20,000 figure I very much doubt that you’d find a particle physicist outside the Xenon1T collaboration who’d give you as much as even odds on the axion theory turning out to be the right one. (Possibly also inside the collaboration, but it’s not polite to ask.)















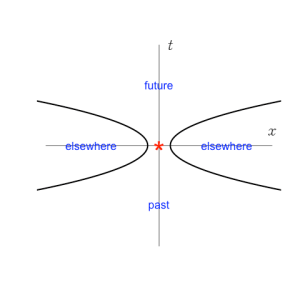
 For any event there must be some events which are not causally connected. The assumption says this is for true for some events, but all events must be similar (as space and time are homogeneous) , so this is true in general. So we can drawa space-time diagram showing the events that are past, future, and elsewhere for an event at the origin.
For any event there must be some events which are not causally connected. The assumption says this is for true for some events, but all events must be similar (as space and time are homogeneous) , so this is true in general. So we can drawa space-time diagram showing the events that are past, future, and elsewhere for an event at the origin.