It is amazing how simple computation can have profound complexity once you start digging.
Let’s take a simple example: finding the average (arithmetic mean) of a set of numbers. It’s the sort of thing that often turns up in real life, as well as in class exercises. Working from scratch you would write a program like (using C as an example: Python or Matlab or other languages would be very similar)
float sum=0;
for(int j=0;j<n;j++){
sum += x[j];
}
float mean=sum/n;
which will compile and run and give the right answer until one day, eventually, you will spot it giving an answer that is wrong. (Well, if you’re lucky you will spot it: if you’re not then its wrong answer could have bad consequences.)
What’s the problem? You won’t find the answer by looking at the code.
The float type indicates that 32 bits are used, shared between a mantissa and and exponent and a sign, and in the usual IEE754 format that gives 24 bits of binary accuracy, corresponding to 7 to 8 decimal places. Which in most cases is plenty.
To help see what’s going on, suppose the computer worked in base 10 rather than base 2, and used 6 digits. So the number 123456 would be stored as 1.23456 x 105 . Now, in that program loop the sum gets bigger and bigger as the values are added. Take a simple case where the values all just happen to be 1.0. Then after you have worked through 1,000,000 of them, the sum is 100000, stored as 1.00000 x 106 . All fine so far. But now add the next value. The sum should be 1000001, but you only have 6 digits so this is also stored as 1.00000 x 106 . Ouch – but the sum is still accurate to 1 part in 106 . But when you add the next value, the same thing happens. If you add 2 million numbers, all ones, the program will tell you that their average is 0.5. Which is not accurate to 1 part in 106 , not nearly!
Going back to the usual but less transparent binary 24 bit precision, the same principles apply. If you add up millions of numbers to find the average, your answer can be seriously wrong. Using double precision gives 53 bit precision, roughly 16 decimal figures, which certainly reduces the problem but doesn’t eliminate it. The case we considered where the numbers are all the same is actually a best-case: if there is a spread in values then the smallest ones will be systematically discarded earlier.
And you’re quite likely to meet datasets with millions of entries. If not today then tomorrow. You may start by finding the mean height of the members of your computing class, for which the program above is fine, but you’ll soon be calculating the mean multiplicity of events in the LHC, or distances of galaxies in the Sloan Digital Sky Survey, or nationwide till receipts for Starbuck’s. And it will bite you.
Fortunately there is an easy remedy. Here’s the safe alternative
float mean=0;
for(int j=0;j<n;j++){
mean += (x[j]-mean)/(j+1);
}
Which is actually one line shorter! The slightly inelegant (j+1) in the denominator arises because C arrays start from zero. Algebraically they are equivalent because

but numerically they are different and the trap is avoided. If you use the second code to average a sequence of 1.0 values, it will return an average of 1.0 forever.
So those (like me) who have once been bitten by the problem will routinely code using running averages rather than totals. Just to be safe. The trick is well known.
What is less well known is how to safely evaluate standard deviations. Here one hits a second problem. The algebra runs
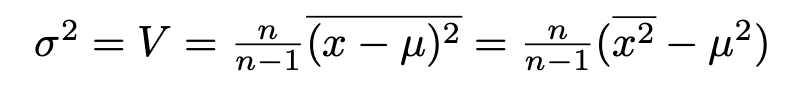
where the n/(n-1) factor, Bessel’s correction, just compensates for the fact that the squared standard deviation or variance of a sample is a biassed estimator of that of the parent. We know how to calculate the mean safely, and we can calculate the mean square in the same way. However we then hit another problem if, as often happens, the mean is large compared to the standard deviation.
Suppose what we’ve got is approximately Gaussian (or normal, if you prefer) with a mean of 100 and a standard deviation of 1. Then the calculation in the right hand bracket will look like
10001 – 10000
which gives the correct value of 1. However we’ve put two five-digit numbers into the sum and got a single digit out. If we were working to 5 significant figures, we’re now only working to 1. If the mean were ~1000 rather than ~100 we’d lose two more. There’s a significant loss of precision here.
If the first rule is not to add two numbers of different magnitude, the second is not to subtract two numbers of similar magnitude. Following these rules is hard because an expression like x+y can be an addition or a subtraction depending on the signs of x and y.
This danger can be avoided by doing the calculation in two passes. On the first pass you calculate the mean, as before. On the second pass you calculate the mean of (x-μ)2 where the differences are sensible, of order of the standard deviation. If your data is in an array this is pretty easy to do, but if it’s being read from a file you have to close and re-open it – and if the values are coming from an online data acquisition system it’s not possible.
And there is a solution. It’s called the Welford Online Algorithm and the code can be written as a simple extension of the running-mean program above
// Welford's algorithm
float mean=x[0];
float V=0;
for(int j=1;j<n;j++){
float oldmean=mean;
mean += (x[j]-mean)/(j+1);
V += ((x[i]- mean)(x[i]-oldmean) - V)/j
}
float sigma=sqrt(V);
The subtractions and the additions are safe. The use of both the old and new values for the mean accounts algebraically, as Welford showed, for the change that the mean makes to the overall variance. The only differences from our original running average program are the need to keep track of both old and new values, and initially defining the mean as the first element (zero), so the loop starts at j=1, avoiding division by zero: the variance estimate from a single value is meaningless. (It might be good to add a check that n>1 to make it generally safe).
I had suspected such an algorithm should exist but, after searching for years, I only found it recently (thanks to Dr Manuel Schiller of Glasgow University). It’s beautiful and its useful and it deserves to be more widely known.
It is amazing how simple computation can have profound complexity once you start digging.
